 nathan leclaire
nathan leclaire
Vibing Best Practices with Claude Code

We’ve been seeing a new meme recently that has been repeated ad nauseum, and I’m already more sick of hearing it than I am of seeing Vance memes, but hey, I’m going to go ahead and throw some more fuel on the memetic dumpster fire. For those of you that landed here from Twitter or whatever, I’m Nathan LeClaire — ex-Docker, ex-Honeycomb hacker, Golang, and open source enthusiast, who, like many these days, is getting sucked into AI enthusiasm.
“Vibe coding” is offloading mental effort that otherwise you’d have to expend in the olden days in code implementation to the AI, and just letting it take the wheel and do its thing, basically copy pasting feedback and code back and forth and trying it out. While it’s been a subject of some controversy, I think it hearkens to the future of software development — software engineers have only limited fucks to give, and are often implementing things that they’ve done many times before, or, might want things that just didn’t used to be worth the effort to figure out when more pressing core functionality was at stake. That’s not to mention, of course, that there is a big barrier to entry that is coming down — people are now able to code up apps with very little code experience, and I think it will do just as much to help people break into the field as trying to tinker with game mods, or Minecraft Redstone, or any other stepping stone that bread crumbed a future developer along. I think in the future we’ll all be supervising little AI agents scattering around, and they’ll naturally keep getting smarter, and smarter.
Of course, many developers have rightfully pointed out that this in its most naive form will lead to a huge mess of unmaintainable spaghetti. And they’re right, at least for the short term, this is a really good way to paint yourself into a corner fast. So having used Claude Code and loved its potential and utility, here are my thoughts on how to vibe code, or kinda-vibe-but-also-be-a-bit-neurotic-code effectively.
Tell Claude What to Do
This should be obvious, yet I have a feeling it will be a disappointingly overlooked element — Claude Code encourages you to create a CLAUDE.md, containing repo-specific instructions about how it should act and what it should do. I will say that despite me including specific instructions, it sometimes just ignores them, but others, like how to lint the code, it will follow. LLMs aren’t magic — they need guidance along the way, and they can’t (yet at least) guess what you want and your conventions, so a few notes like, Always use slog for structured logging, or, Identify nice fields to do .SetAttribute on OpenTelemetry Spans and add them as custom attributes, or Run goimports on go files after every change, will go a long way to keeping you from going insane.
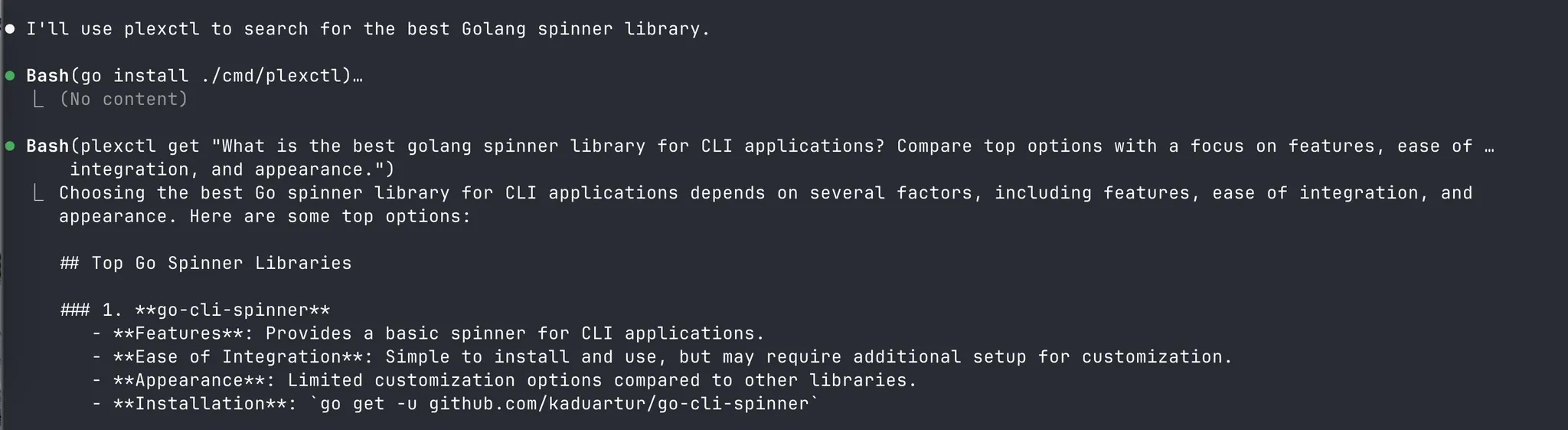
To that end, instruct it to use stackable tools that enable it to go above and beyond. Hell, give it a read only API key and tell it to knock itself out, say, inspecting your AWS infrastructure, if you need to expand on Terraform scripts. If the fucking thing knows how to use grep and sed and that’s already useful, imagine plugging it into more sophisticated systems over time. That’s why I wrote up plexctl , which is a no frills Golang CLI for the Perplexity API. Sometimes Perplexity is just really good at being able to reference docs and up to date information online in a way that the other models are not, so I want Claude to be able to reach for it when it can.
Then, there’s planning — even though I’m pretty sure it’s doing 3.7 thinking in a lot of places behind the scenes, realistically I think o1-pro is still a smarter model right now. Claude, while being wildly enthusiastic and ruthlessly effective given the right directions, just doesn’t seem to “grasp” my intent and sophisticated implementation as much as o1-pro does. I actually think this could change soon because Anthropic is a really smart lab (and I haven’t spent enough time using 3.7 in anger to truly commit to a strong opinion here, this is just a gut check). But yeah, I think even just experimentally we’ll be ping ponging things back and forth from various agents and models for a while. And if one is a great planner and implementer, it makes sense that you should use it to distill stuff to guide other models. In a truly self indulgent meta loop, here’s one stab at a prompt for o1-pro for this I came up with using Perplexity:
You are an exceptionally intelligent AI architect tasked with creating a clear, structured, and detailed implementation plan for a diligent but less sophisticated AI assistant to execute. Your goal is to design a step-by-step strategy that the implementer AI can follow precisely to produce fully functional, specification-compliant code that adheres strictly to all linting standards and best practices. Begin by clearly defining the overall objective and breaking it down into sequential, manageable tasks using XML tags to separate instructions (
<instruction>), context (<context>), and code examples (<code_example>). Explicitly assign yourself the role of a senior software architect and the implementer AI as a meticulous junior developer. Provide vivid, concrete code snippets demonstrating particularly tricky or error-prone components directly within<code_example>tags, ensuring these snippets are concise, fully commented, and ready for direct implementation without ambiguity. Prefill your response with the phrase “Here is your detailed implementation plan:” to enforce immediate clarity and structure. Include a separate XML-tagged section (<thinking>) where you explicitly reason step-by-step through potential pitfalls and edge cases, clearly stating assumptions and how you’ve accounted for them in your instructions. Conclude by instructing the implementer AI to verify all provided code snippets against standard linting tools (e.g., ESLint for JavaScript or Pylint for Python) before integrating into the final deliverable, emphasizing strict adherence to specifications and coding standards.
I then literally just copy paste the result into Claude Code and let it rip.
Relentlessly Lint, Test and Format
When vibe coding up plexctl this was something that kept me sane, and I think set up a good foundation for the future — I added aggressive linting and formatting rules and told Claude to check it on the regular. My golang-cilint config looks like this:
run:
timeout: 5m
modules-download-mode: readonly
allow-parallel-runners: true
go: "1.23"
linters:
enable:
- errcheck
- gosimple
- govet
- ineffassign
- staticcheck
- unused
- gocritic
- goconst
- unparam
- stylecheck
- testifylint
- wastedassign
- gosec
- exhaustive
- contextcheck
- paralleltest
- perfsprint
- nonamedreturns
- nilerr
- whitespace
- asasalint
- errorlint
- mnd
- errname
- funlen
- cyclop
- nestif
- protogetter
- gofmt
- goimports
- misspell
- bodyclose
linters-settings:
gofmt:
simplify: true
goimports:
local-prefixes: github.com/nathanleclaire/plexctl
revive:
rules:
- name: exported
severity: error
disabled: false
funlen:
lines: 60
statements: 40
nestif:
min-complexity: 3
cyclop:
max-complexity: 10
issues:
exclude-use-default: false
max-issues-per-linter: 0
max-same-issues: 0
This is an arguably overly strict and sometimes maddening set of rules to work with, but having devoted some love to it (and, nicely, one can mostly reduce the errors pretty mechanically with o1-pro or Claude itself, again leaving mental effort free to think about other things) — I am convinced it results in much, much more understandable and maintainable code spit out by these things, especially the function lengths, cyclomatic complexity, and magic variable rules. These LLMs right now love to output code that technically works but looks and, well, feels god awful. The sloppification factor increases linearly with the amount of lines you write without cleaning things up, and it’s hard for me to believe that even the LLMs themselves will have performance that is optimal working with that kind of code over time. But you can and should programmatically keep at least certain classes of issues from getting out of hand.
I think there’s also a human taste factor you need to apply — most decent rounds of back and forth vibing should get a human pass to make sure the LLM didn’t do anything too cringe, even if it is working. As just one example, Claude and o1-pro seem to love to just splat in map[string]interface{} to places where obviously most Go programmers would use a struct. This, over time, would drive any experienced programmer up the wall.
Their concurrency habits are also a bit sus.
So, my workflow tends to look something like —
- Have a nice think about how to be specific about what I want to update and what the “acceptance criteria” will be.
- Paste existing code into o1-pro and ask for a plan
- Boot up Claude Code and paste the plan into it
- Wait and vibe out
- Test the functionality I’m targeting by hand
- Repeat 2-5 if needed
- Format and lint the code by hand if needed
- Cry and ask myself why I’m using LLMs when I see the huge pile of lint errors
- Ask o1-pro how to fix them
- Paste the results back into Claude
This usually then gets a fairly passable final result, and I then go in and do some “human linting”, where I pass it over, kind of like you might do with a code review (and indeed, I think Claude Code offers literally doing this with Github, I just haven’t tried it yet.) I find it does a lot of cringe things that I need to rein in, but still find it worth it because I’d rather correct code than blast through mental cycles trying to write it myself, especially if it’s just some flourish. Copilot, is, of course, useful for this.
In other projects, when I’ve leaned on LLMs for implementation, I benefited a lot from a comprehensive test suite, especially integration tests that actually check the functionality itself. LLMs are happy to go and delete or hard code your unit tests, if you don’t supervise them closely, so you need to keep an eye out that they don’t just paperclip your safety mechanisms out.
Don’t Be Afraid to Give Up

Keeping the bonkers puppy of a token generator from getting too carried away and coding up a pile of bugs that I will drown in before I can fix them is a perpetual challenge. It’s great that we can crank out so much code! Unfortunately, it means we are generating code that rots faster than ever, and any step in the wrong direction, starts compounding negatively very quickly. If the LLM gets confused about your intents, we are still in a world where it will somewhat latch on to previous, bad results in the thread, and it’s worth just… giving up and starting over in a new thread.
Relatedly, a thing I’d call out is, don’t just turn your brain off. Take some time to think about how the code you’re adding works and why the LLM is doing it that way, and whether it truly makes sense. And, of course, if you can’t figure it out, if you really need that ninja backflip of a flourish you’re wasting hours trying to get Claude to implement correctly.
To Vibe or Not To Vibe
I think what we’re seeing is a large scale migration to freeing up programmers’ mental cycles and offload tasks to agents. What the end result of all this will be is anybody’s guess — however, it seems clear it will make life as a junior engineer harder, since a lot of the things we’re doing this way now used to be their turf. I have a feeling it’s coming for the rest of us, in terms of what we used to do for a role at least — most likely, in the future we will be less “programmers” as “AI agent orchestrators and debuggers”. So, I think a lot of people go too hard on “vibe coding”. It’s obviously here to stay, maybe not in this exact form, or in the sense of “being able to make full blown apps without knowing any code at all”, but certainly in terms of supervising, editing, and iterating on the output of agents and chat systems.
Hopefully I can save some people from future monstrous spaghetti messes with some of these thoughts. Until next time, stay sassy Internet.
- Nathan